
Tutti parlano di GPT-5. Nessuno l’ha visto. Ma i meme sono già ovunque
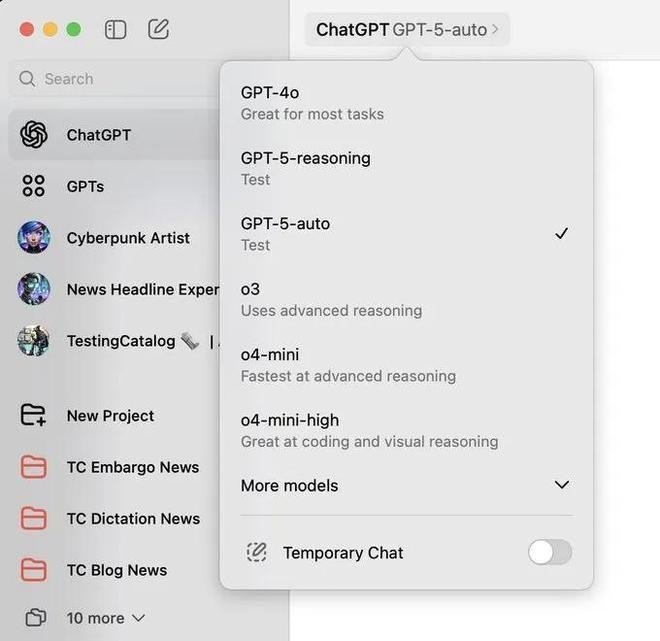
GPT-5 non è ancora apparso e gli internauti hanno iniziato a creare ogni genere di meme per lamentarsi. In effetti, le voci su GPT-5 non si sono fermate negli ultimi giorni. Innanzitutto, alcuni internauti hanno trovato tracce dei modelli GPT-5-Auto e GPT-5-Reasoning nell’applicazione ChatGPT di macOS.
Poi hanno rivelato che anche Microsoft Copilot e Cursor sono stati segretamente collegati per testare GPT-5. Il 1° agosto, The Information ha pubblicato un lungo articolo intitolato “Inside OpenAI’s Rocky Path to GPT-5”, rivelando ulteriori informazioni riservate su GPT-5.
GPT-5 è migliorato, ma il salto di prestazioni non è così grande come prima. Lo scorso dicembre, OpenAI ha presentato i risultati della sua tecnologia Test-Time Scaling, una svolta fondamentale nelle capacità dei modelli di grandi dimensioni nell’era post-pre-addestramento.
Il test ha dimostrato che le prestazioni dell’IA continuano a migliorare quando ha più tempo e potenza di calcolo per elaborare le attività. Questo approccio tecnico ha già dimostrato la sua efficacia nell’applicazione pratica di OpenAI-o1 e DeepSeek-R1. Sembra che gli utenti di ChatGPT rimarranno colpiti dalle potenti capacità di questa nuova IA. Tuttavia, l’entusiasmo non è durato a lungo.
Secondo due persone coinvolte nel suo sviluppo, quando i ricercatori di OpenAI hanno adattato la nuova IA in una versione basata sulla chat, o3, in grado di rispondere ai comandi degli utenti di ChatGPT, i miglioramenti in termini di prestazioni rispetto ai benchmark precedenti sono in gran parte scomparsi.
Questo è solo un esempio delle numerose sfide tecniche che OpenAI ha dovuto affrontare quest’anno. Le crescenti difficoltà stanno rallentando il ritmo dello sviluppo dell’intelligenza artificiale e potrebbero persino influire sul business di ChatGPT, un’applicazione di intelligenza artificiale di successo.
Con l’imminente rilascio di GPT-5, si dice che i ricercatori di OpenAI abbiano trovato una soluzione. Secondo fonti e ingegneri interni di OpenAI, il prossimo modello di intelligenza artificiale di punta di OpenAI, GPT-5, avrà capacità notevolmente migliorate in programmazione, matematica e altri ambiti.
Una fonte ha affermato che il nuovo modello è più efficace nell’aggiungere funzionalità durante la scrittura del codice applicativo (“vibe coding”), rendendolo più facile da usare e più gradevole esteticamente. Ha inoltre affermato che GPT-5 è migliore del suo predecessore anche nel guidare gli agenti di intelligenza artificiale a gestire attività complesse con una supervisione umana minima. Ad esempio, può seguire istruzioni complesse e un elenco di regole per determinare quando il servizio clienti automatizzato debba emettere un rimborso, mentre i modelli precedenti dovevano prima testare diversi casi complessi (ad esempio, casi limite) prima di poter elaborare tale rimborso.
Un’altra persona a conoscenza della questione ha affermato che i miglioramenti non possono eguagliare i balzi in termini di prestazioni osservati nei precedenti modelli GPT, come i miglioramenti tra GPT-3 nel 2020 e GPT-4 nel 2023. Il rallentamento nei guadagni di prestazioni che OpenAI ha sperimentato negli ultimi 12 mesi suggerisce che potrebbe avere difficoltà a superare il suo principale rivale, almeno in termini di capacità di intelligenza artificiale.
Gli attuali modelli di OpenAI hanno già creato un valore commerciale significativo tramite ChatGPT e varie applicazioni, e anche i miglioramenti incrementali aumenteranno la domanda dei clienti. Questi miglioramenti daranno anche fiducia agli investitori per finanziare il piano di OpenAI di investire 45 miliardi di dollari nei prossimi tre anni e mezzo per l’acquisto di GPU per lo sviluppo e l’esecuzione dei prodotti.
Migliorare le capacità di codifica automatizzata è diventata la massima priorità di OpenAI. I recenti progressi contribuiscono anche a spiegare perché i dirigenti di OpenAI abbiano dichiarato nelle ultime settimane ad alcuni investitori di credere che l’azienda possa raggiungere l’obiettivo “GPT-8”. Questa affermazione è in linea con le dichiarazioni pubbliche del CEO Sam Altman, secondo cui OpenAI, con le sue attuali conoscenze tecniche, è sulla buona strada per creare un’intelligenza artificiale generale (AGI), che rivaleggia con le capacità degli esseri umani più intelligenti.
Sebbene siamo ancora lontani dal raggiungimento dell’AGI, il modello GPT-5, che verrà rilasciato a breve, potrebbe avere un certo fascino, che va oltre una migliore codifica e un ragionamento migliore. Microsoft ha i diritti esclusivi per utilizzare la proprietà intellettuale di OpenAI e alcuni dirigenti dell’azienda hanno detto ai dipendenti che i test del modello hanno dimostrato che GPT-5 è in grado di generare codici di qualità superiore e altre risposte basate su testo senza consumare più risorse di elaborazione, secondo un dipendente Microsoft a conoscenza della questione.
Ciò è dovuto in parte al fatto che, rispetto ai modelli precedenti, è più efficace nel valutare quali attività richiedono relativamente più o meno risorse di elaborazione, ha affermato la persona. La valutazione interna di OpenAI dimostra che il miglioramento della capacità dell’intelligenza artificiale di eseguire automaticamente attività di codifica è diventata la priorità principale di OpenAI dopo che il concorrente Anthropic ha preso l’iniziativa lo scorso anno nello sviluppo e nella vendita di tali modelli a sviluppatori di software e assistenti di codifica come Cursor.
I progressi di OpenAI non sono stati facili, poiché quest’anno i suoi ricercatori e la sua dirigenza hanno dovuto affrontare nuove pressioni. Innanzitutto c’è il delicato rapporto con Microsoft. Sebbene Microsoft sia il maggiore azionista esterno di OpenAI e abbia il diritto di utilizzare alcune delle tecnologie di OpenAI fino al 2030 in base a un accordo contrattuale tra le due parti, alcuni ricercatori senior di OpenAI non sono d’accordo a cedere le loro innovazioni e invenzioni a Microsoft.
Anche in termini finanziari, Microsoft e OpenAI hanno un rapporto di collaborazione molto stretto, ma ci sono controversie sui termini specifici della cooperazione ed entrambe le parti chiedono all’altra parte di fare alcune concessioni. OpenAI spera di prepararsi a una futura IPO ristrutturando la sua divisione a scopo di lucro. Sebbene alcuni dettagli rimangano incerti, entrambe le parti hanno raggiunto un consenso preliminare su alcuni aspetti importanti, come la potenziale acquisizione di circa il 33% del capitale di OpenAI da parte di Microsoft dopo la ristrutturazione.
La seconda è che continua il bracconaggio degli ingegneri. Di recente, Meta ha speso molti soldi per sottrarre più di una dozzina di ricercatori a OpenAI, alcuni dei quali avevano partecipato al recente lavoro di OpenAI sul miglioramento della tecnologia. Queste perdite di talenti e i conseguenti adeguamenti del personale mettono sotto pressione la dirigenza di OpenAI.
La scorsa settimana, Jerry Tworek, vicepresidente della ricerca di OpenAI, si è lamentato con il suo capo, Mark Chen, dei cambiamenti nel team in un messaggio interno su Slack, visto da molti colleghi. Tworek ha dichiarato di aver dovuto prendersi una settimana di ferie per rivalutare la situazione, ma in seguito non ha usufruito delle ferie.
Sebbene OpenAI abbia compiuto alcuni progressi commerciali, all’interno dell’azienda persistono ancora alcune preoccupazioni sulla sua capacità di continuare a migliorare l’intelligenza artificiale e mantenere la sua posizione di leadership, soprattutto di fronte a concorrenti ben finanziati.
Nella seconda metà del 2024, OpenAI ha sviluppato un modello chiamato Orion, che inizialmente aveva pianificato di rilasciare come GPT-5, prevedendo che le sue prestazioni sarebbero state superiori a quelle del modello GPT-40 esistente. Tuttavia, Orion non è riuscito a ottenere il miglioramento previsto, quindi OpenAI lo ha rilasciato come GPT-4.5, che alla fine non ha avuto un impatto significativo.
Il fallimento di Orion è dovuto in parte alle limitazioni nella fase di pre-addestramento. Il pre-addestramento è il primo passo nello sviluppo del modello, che richiede l’elaborazione di grandi quantità di dati per comprendere le connessioni tra i concetti. Di fronte alla carenza di dati di alta qualità, OpenAI ha anche scoperto che le ottimizzazioni apportate al modello di Orion, pur essendo efficaci quando il modello era di piccole dimensioni, diventavano inefficaci con l’aumentare delle dimensioni.
L'articolo Tutti parlano di GPT-5. Nessuno l’ha visto. Ma i meme sono già ovunque proviene da il blog della sicurezza informatica.