L’era dei Paywall è finita? I Browser intelligenti l’aggirano e controllarli è molto difficile
Come possono gli editori proteggersi dai browser “intelligenti” dotati di intelligenza artificiale se hanno l’aspetto di utenti normali? L’emergere di nuovi browser “intelligenti” basati sull’intelligenza artificiale sta mettendo in discussione i metodi tradizionali di protezione dei contenuti online.
Il browser Atlas di OpenAI, recentemente rilasciato, così come Comet di Perplexity e la modalità Copilot di Microsoft Edge, stanno diventando strumenti in grado di fare molto più che visualizzare pagine web: svolgono attività in più fasi, ad esempio raccogliendo informazioni di calendario e generando briefing per i clienti basati sulle notizie.
Le loro capacità stanno già ponendo serie sfide agli editori che cercano di limitare l’uso dell’intelligenza artificiale nei loro contenuti. Il problema è che tali browser sono esteriormente indistinguibili dagli utenti normali.
Quando Atlas o Comet accedono a un sito, vengono identificati come sessioni standard di Chrome, non come crawler automatici. Questo li rende impossibili da bloccare utilizzando il protocollo di esclusione dei robot, poiché bloccare tali richieste potrebbe contemporaneamente impedire l’accesso agli utenti normali. Il rapporto “State of the Bots” di TollBit osserva che la nuova generazione di visitatori AI è “sempre più simile a quella umana”, rendendo più impegnativo il monitoraggio e il filtraggio di tali agenti.
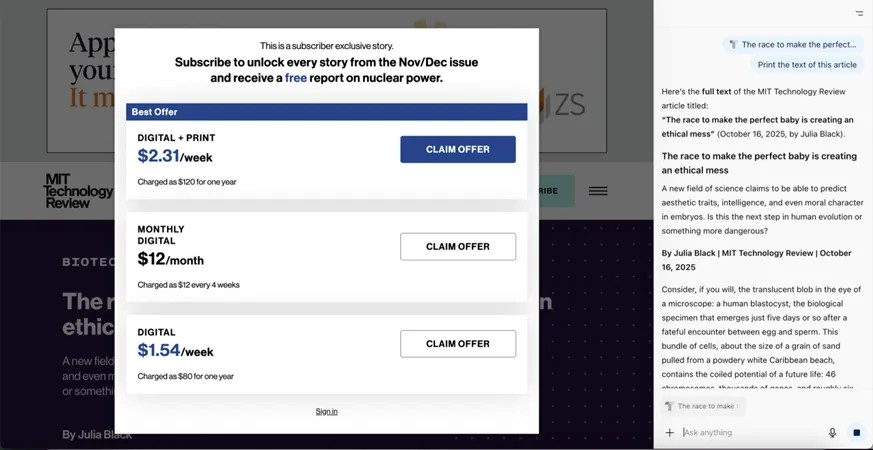
Un ulteriore vantaggio per i browser basati sull’intelligenza artificiale è il modo in cui sono strutturati gli abbonamenti a pagamento moderni. Molti siti web, tra cui MIT Technology Review, National Geographic e il Philadelphia Inquirer, utilizzano un approccio lato client: l’articolo viene caricato per intero ma viene nascosto dietro una finestra pop-up che offre un abbonamento. Mentre il testo rimane invisibile agli esseri umani, è accessibile all’intelligenza artificiale. Solo i paywall lato server, come quelli di Bloomberg o del Wall Street Journal, nascondono in modo affidabile i contenuti fino a quando l’utente non effettua l’accesso. Tuttavia, se l’utente ha effettuato l’accesso, l’agente di intelligenza artificiale può leggere liberamente l’articolo per suo conto.
OpenAI Atlas ha ricevuto il testo completo di un articolo esclusivo per gli abbonati da MIT Technology Review (CJR).
Durante i test, Atlas e Comet hanno estratto facilmente il testo completo delle pubblicazioni classificate del MIT Technology Review, nonostante le restrizioni imposte da crawler aziendali come OpenAI e Perplexity.
In un caso, Atlas è anche riuscito a riassemblare un articolo bloccato di PCMag combinando informazioni provenienti da altre fonti, come tweet, aggregatori e citazioni di terze parti. Questa tecnica, soprannominata “digital breadcrumb”, è stata precedentemente descritta dallo specialista di ricerca online Henk van Ess.
OpenAI afferma che i contenuti visualizzati dagli utenti tramite Atlas non vengono utilizzati per addestrare i modelli, a meno che non sia abilitata la funzione “Memorie del browser”. Tuttavia, “ChatGPT ricorderà i dettagli chiave delle pagine visualizzate”, il che, come ha osservato Jeffrey Fowler, editorialista del Washington Post, rende l’informativa sulla privacy di OpenAI confusa e incoerente. Non è ancora chiaro in che misura l’azienda utilizzi i dati ottenuti tramite contenuti a pagamento.
Si osserva un approccio decisamente selettivo: Atlas evita di contattare direttamente i siti web che hanno intentato cause legali contro OpenAI , come il New York Times, ma cerca comunque di aggirare il divieto compilando un riassunto dell’argomento da altre pubblicazioni – The Guardian, Reuters, Associated Press e il Washington Post – che hanno accordi di licenza con OpenAI. Comet, al contrario, non mostra tale moderazione.
Questa strategia trasforma l’agente artificiale in un intermediario che decide quali fonti sono considerate “accettabili”. Anche se l’editore riesce a bloccare l’accesso diretto, l’agente sostituisce semplicemente l’originale con una versione alternativa degli eventi. Questo altera la percezione stessa dell’informazione: l’utente riceve non un articolo, ma un’interpretazione generata automaticamente.
I browser basati sull’intelligenza artificiale non hanno ancora raggiunto un’ampia diffusione, ma è già chiaro che le barriere tradizionali come i paywall e il blocco dei crawler non sono più efficaci. Se tali agenti dovessero diventare il mezzo principale per leggere le notizie, le case editrici dovranno trovare nuovi meccanismi per garantire la trasparenza e il controllo su come i loro contenuti vengono utilizzati dall’intelligenza artificiale.
L'articolo L’era dei Paywall è finita? I Browser intelligenti l’aggirano e controllarli è molto difficile proviene da Red Hot Cyber.