Cloudflare blackout globale: si è trattato di un errore tecnico interno. Scopriamo la causa
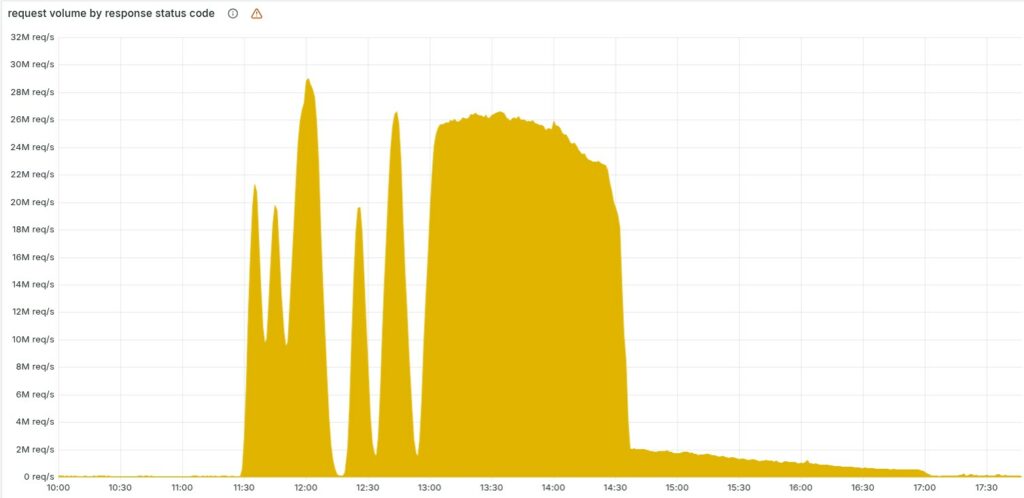
Il 18 novembre 2025, alle 11:20 UTC, una parte significativa dell’infrastruttura globale di Cloudflare ha improvvisamente cessato di instradare correttamente il traffico Internet, mostrando a milioni di utenti di tutto il mondo una pagina di errore HTTP che riportava un malfunzionamento interno della rete dell’azienda.
L’interruzione ha colpito una vasta gamma di servizi – dal CDN ai sistemi di autenticazione Access – generando un’ondata anomala di errori 5xx. Secondo quanto riportato da Cloudflare che lo riporta con estrema trasparenza, la causa non è stata un attacco informatico ma un errore tecnico interno, scatenato da una modifica alle autorizzazioni di un cluster database.
Cloudflare ha precisato fin da subito che nessuna attività malevola, diretta o indiretta, è stata responsabile dell’incidente. L’interruzione, come riporta il comunicato di post mortem, è stata innescata da un cambiamento a un sistema di permessi di un database ClickHouse che, per un effetto collaterale non previsto, ha generato un file di configurazione anomalo utilizzato dal sistema di Bot Management.
Tale “feature file”, contenente le caratteristiche su cui si basa il modello di machine learning anti-bot dell’azienda, ha improvvisamente raddoppiato le sue dimensioni a causa della presenza di numerose righe duplicate.
Questo file, aggiornato automaticamente ogni pochi minuti e propagato rapidamente a tutta la rete globale di Cloudflare, ha superato il limite previsto dal software del core proxy, causando un errore critico.
Il sistema che esegue l’instradamento del traffico – noto internamente come FL e nella sua nuova versione FL2 – utilizza infatti limiti rigidi per la preallocazione di memoria, con un massimo fissato a 200 feature. Il file corrotto ne conteneva più del doppio, facendo scattare un “panic” del modulo Bot Management e interrompendo l’elaborazione delle richieste.
Nei primi minuti dell’incidente, l’andamento irregolare degli errori ha portato i team di Cloudflare a sospettare inizialmente un massiccio attacco DDoS: il sistema sembrava infatti riprendersi spontaneamente per poi ricadere nel guasto, un comportamento insolito per un errore interno.
Questa fluttuazione era dovuta alla natura distribuita dei database coinvolti. Il file veniva generato ogni cinque minuti e, poiché solo alcune parti del cluster erano state aggiornate, il sistema produceva alternativamente file “buoni” e file “difettosi”, propagandoli istantaneamente a tutti i server.
Nell blog si legge :
“Ci scusiamo per l’impatto sui nostri clienti e su Internet in generale. Data l’importanza di Cloudflare nell’ecosistema Internet, qualsiasi interruzione di uno qualsiasi dei nostri sistemi è inaccettabile. Il fatto che ci sia stato un periodo di tempo in cui la nostra rete non è stata in grado di instradare il traffico è profondamente doloroso per ogni membro del nostro team. Sappiamo di avervi deluso oggi“.
Con il passare del tempo, l’intero cluster è stato aggiornato e le generazioni di file “buoni” sono cessate, stabilizzando il sistema nello stato di errore totale. A complicare ulteriormente la diagnosi è intervenuta una coincidenza inaspettata: il sito di stato di Cloudflare, ospitato esternamente e quindi indipendente dall’infrastruttura dell’azienda, è risultato irraggiungibile nello stesso momento, alimentando il timore di un attacco coordinato su più fronti.
La situazione ha iniziato a normalizzarsi alle 14:30 UTC, quando gli ingegneri hanno individuato la radice del problema e interrotto la propagazione del file corrotto. È stato quindi distribuito manualmente un file di configurazione corretto e forzato un riavvio del core proxy. La piena stabilità dell’infrastruttura è stata ripristinata alle 17:06 UTC, dopo un lavoro di recupero dei servizi che avevano accumulato code, latenze e stati incoerenti.
Diversi servizi chiave hanno subito impatti significativi: il CDN ha risposto con errori 5xx, il sistema di autenticazione Turnstile non riusciva a caricarsi, Workers KV restituiva errori elevati e l’accesso alla dashboard risultava bloccato per la maggior parte degli utenti. Anche il servizio Email Security ha visto diminuire temporaneamente la propria capacità di rilevare lo spam a causa della perdita di accesso a una fonte IP reputazionale. Il sistema di Access ha registrato un’ondata di fallimenti di autenticazione, impedendo a molti utenti di raggiungere le applicazioni protette.
L’interruzione ha evidenziato vulnerabilità legate alla gestione distribuita della configurazione e alla dipendenza da file generati automaticamente con aggiornamenti rapidi. Cloudflare ha ammesso che una parte delle deduzioni del suo team durante i primi minuti dell’incidente si è basata su segnali fuorvianti – come il down del sito di stato – che hanno ritardato la corretta diagnosi del guasto. L’azienda ha promesso un piano di intervento strutturato per evitare che un singolo file di configurazione possa nuovamente bloccare segmenti così ampi della sua rete globale.
Cloudflare ha riconosciuto con grande trasparenza la gravità dell’incidente, sottolineando come ogni minuto di interruzione abbia un impatto significativo sull’intero ecosistema Internet, dato il ruolo centrale che la sua rete svolge.
L’azienda ha annunciato che questo primo resoconto sarà seguito da ulteriori aggiornamenti e da una revisione completa dei processi interni di generazione delle configurazioni e gestione degli errori di memoria, con l’obiettivo dichiarato di evitare che un evento simile possa ripetersi.
L'articolo Cloudflare blackout globale: si è trattato di un errore tecnico interno. Scopriamo la causa proviene da Red Hot Cyber.