An AI By Any Other Name
While there are many AI programs these days, they don’t all work in the same way. Most large language model “chatbots” generate text by taking input tokens and predicting the next token of the sequence. However, image generators like Stable Diffusion use a different approach. The method is, unsurprisingly, called diffusion. How does it work? [Nathan Barry] wants to show you, using a tiny demo called tiny-diffusion you can try yourself. It generates — sort of — Shakespeare.
For Stable Diffusion, training begins with an image and an associated prompt. Then the training system repeatedly adds noise and learns how the image degenerates step-by-step to noise. At generation time, the model starts with noise and reverses the process, and an image comes out. This is a bit simplified, but since something like Stable Diffusion deals with millions of pixels and huge data sets, it can be hard to train and visualize its operation.
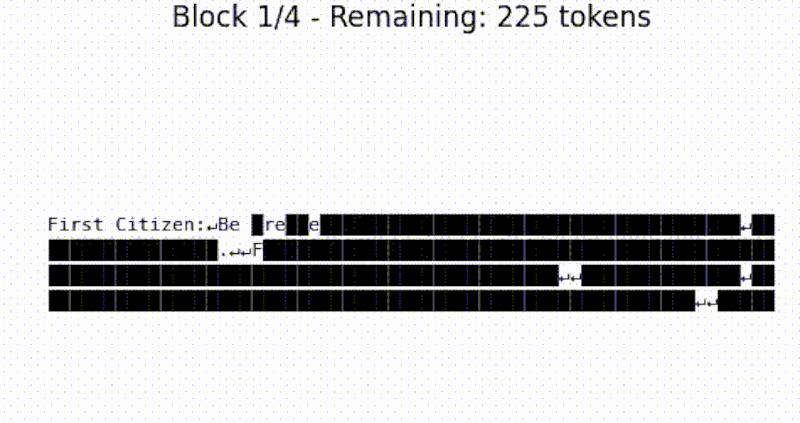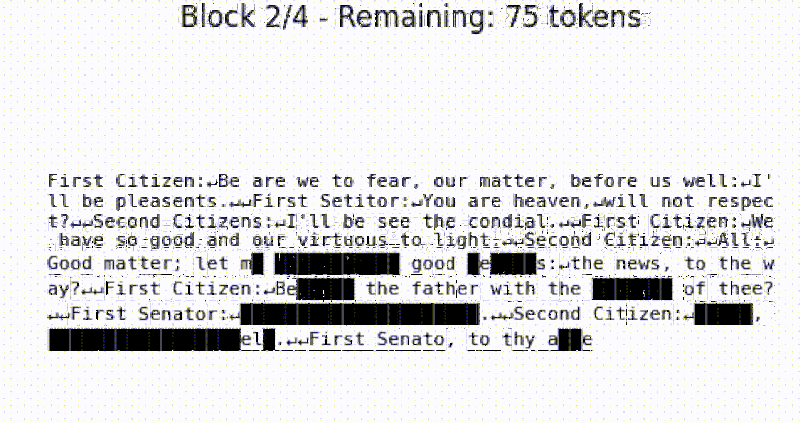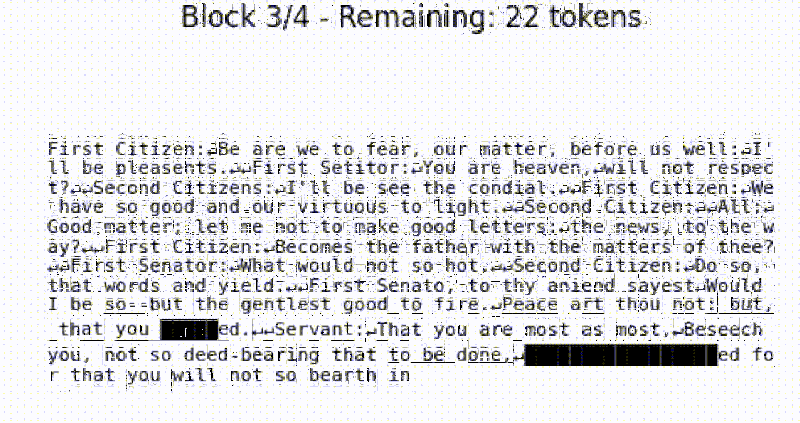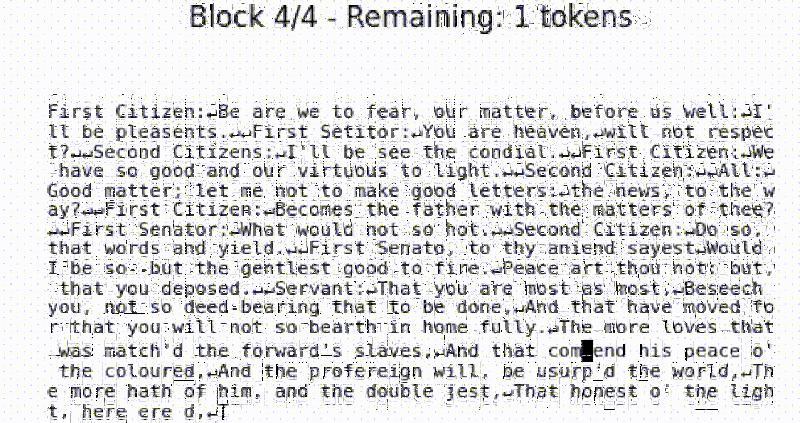
The beauty of tiny-diffusion is that it works on characters, so you can actually see what the denoising process is doing. It is small enough to run locally, if you consider 10.7 million parameters small. It is pretrained on Tiny Shakespeare, so what comes out is somewhat Shakespearean.
The default training reportedly took about 30 minutes on four NVIDIA A100s. You can retrain the model if you like and presumably use other datasets. What’s interesting is that you can visualize the journey the text takes from noise to prose right on the terminal.
Want to dive deeper into diffusion? We can help. Our favorite way to prompt for images is with music.
hackaday.com/2025/11/16/an-ai-…