How To Train A New Voice For Piper With Only A Single Phrase
[Cal Bryant] hacked together a home automation system years ago, which more recently utilizes Piper TTS (text-to-speech) voices for various undisclosed purposes. Not satisfied with the robotic-sounding standard voices available, [Cal] set about an experiment to fine-tune the Piper TTS AI voice model using a clone of a single phrase created by a commercial TTS voice as a starting point.
Before the release of Piper TTS in 2023, existing free-to-use TTS systems such as espeak and Festival sounded robotic and flat. Piper delivered much more natural-sounding output, without requiring massive resources to run. To change the voice style, the Piper AI model can be either retrained from scratch or fine-tuned with less effort. In the latter case, the problem to be solved first was how to generate the necessary volume of training phrases to run the fine-tuning of Piper’s AI model. This was solved using a heavyweight AI model, ChatterBox, which is capable of so-called zero-shot training. Check out the Chatterbox demo here.
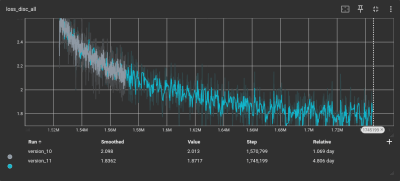
As the loss function gets smaller, the model’s accuracy gets better
Training began with a corpus of test phrases in text format to ensure decent coverage of everyday English. [Cal] used ChatterBox to clone audio from a single test phrase generated by a ‘mystery TTS system’ and created 1,300 test phrases from this new voice. This audio set served as training data to fine-tune the Piper AI model on the lashed-up GPU rig.
To verify accuracy, [Cal] used OpenAI’s Whisper software to transcribe the audio back to text, in order to compare with the original text corpus. To overcome issues with punctuation and differences between US and UK English, the text was converted into phonemes using espeak-ng, resulting in a 98% phrase matching accuracy.
After down-sampling the training set using SoX, it was ready for the Piper TTS training system. Despite all the preparation, running the software felt anticlimactic. A few inconsistencies in the dataset necessitated the removal of some data points. After five days of training parked outside in the shade due to concerns about heat, TensorBoard indicated that the model’s loss function was converging. That’s AI-speak for: the model was tuned and ready for action! We think it sounds pretty slick.
If all this new-fangled AI speech synthesis is too complex and, well, a bit creepy for you, may we offer a more 1980s solution to making stuff talk? Finally, most people take the ability to speak for granted, until they can no longer do so. Here’s a team using cutting-edge AI to give people back that ability.
hackaday.com/2025/07/09/how-to…